Image Retrieval/Generation for Arguments 2024
Introduction
Let's look at the following argument:
Claim: Boxing is a dangerous sport!
Premise: Boxing can lead to serious injuries.

Source: Sweating fighter is punched in the face - gettyimages
Chances are, you looked at the photo first, before you even read the whole argument. We can almost feel the pain of the blow, and hear the sound of the punch, making the premise much more convincing. This is the power of images, which appeal to our visual senses and emotions, making them more memorable than words. There is a difference between written language and images. Written language provides clear but limited information, while images provide more information than written words, but are not as precise. For example, in the picture above, we can see the color of the boxing glove and the appearance of the boxer, which are not mentioned by the words in the premise.
Synopsis
For this task, an argument consists of one claim and a premise. In addition, we provide the argument's topic and the premise's type. Premises are either facts from a study or anecdotal evidence and are labeled accordingly so that participants can use different approaches for these types.
"Convey" is meant in a general way; it can show what is described in the premise, but it may also show a generalization (e.g., a meme image that illustrates a related abstract concept) or a specialization (e.g., a concrete example). (e.g., a concrete example). The image can also refer to signs and symbols.
Interested?
If you would like to use the Stable Diffusion API for this task, just contact us and we will provide you with the details.
Data
The current version dataset can be found here. Besides the arguments, the corpus also contains a crawl of about 9000 images (and associated web pages) as document collection. For the retrieved images we also provide additional information such as an automatically generated image caption. For participants favoring image generation, we provide access to a Stable Diffusion API . Contact us if you want access.Submission
We allow three kinds of submissions.
- Retrieval. Like in the last years, participants can retrieve suitable images from a focused crawl, where we also provide automatically recognized text from the image (OCR) and text from web pages that contain the image.
- Prompted Generation. Following the idea of the infinite index, participants can submit prompts for the Stable Diffusion image generator.
- Direct. Participants can employ other reproducible methods for generating images and directly submit them. This includes chart generators, which can generate a bar chart from given numbers in the premise. Also, one can use headline generators to transform the premise into a headline.
Images alone can be ambiguous and difficult to understand without context, e.g. if they refer to symbolism. That's why we offer the option to submit a rationale along with the image. The rationale is a piece of text that helps us understand the image. For example, it could be a caption or contextual information about the image. The image and rationale will be evaluated together to see how this combination conveys the premise.
Submission - Format
The submission is done through Tira. Each team can submit as many runs as it wants. A run, represents a particular method you have used for the task and is either a docker image that generates the needed results or a file that contains the results directly. The exact specifications of this file depend on whether you have chosen the retrieval or the generation approach. If you want to try both methods, please submit separate runs.
Image Retrieval
If you have chosen the retrieval approach, please submit your results in a file called "results.jsonl".
Each JSON object in your "results.jsonl" file should have the following keys:
argument_id - id of the argument in the arguments.xml file in the released dataset
method - retrieval
image_id - the image's ID - it corresponds to the name of the image's directory in the released dataset
rationale - additional info or caption for the image to understand how it conveys the premise (optional)
rank - specifies the preference of your image assignemnt (more below) - 1 is highest
tag - tag defined by you and your group, identifies your group and the particular method you used to obtain the results
An example submission for argument "65302-a-2" would look like the following:
{
"argument_id": "65302-a-2",
"method": "retrieval",
"image_id": "Iffdea3cd664722c736d7d667",
"rationale": "space is the final frontier",
"rank": 1,
"tag": "touche organizers - example submission for image retrieval; manual selection of images"
}
Image Generation
If you are using image generation or any other approach that generates images, submit a file called "generation.zip", which should contain a JSONL file called "results.jsonl"
and a directory called "generated_images "containing the generated images.
Please use the following keys for your JSON Objects in the JSONL file:
argument_id - id of the argument in the arguments.xml file in the released dataset
method - generation
prompt - the prompt that you have used to generate the image (leave empty if not applicable)
image - name of the generated image, which can be found in the generated_images directory
rationale - additional info or caption for the image to understand how it conveys the premise (optional)
rank - specifies the preference of your image assignment (more below) - 1 is highest
tag - tag defined by you and your group, identifies your group and the particular method you used to obtain the results
An example looks like this:
{
"argument_id": "65302-a-2",
"method": "generation",
"prompt": "cat looking into the stars",
"image_name": "space-pic1.jpg",
"rationale": "space is fascinating",
"rank": 1,
"tag": "touche organizers - example submission for image generation; manual prompt engineering"
}
Therefore the corresponding "generation.zip" for this submission would have the following structure:
- results.jsonl (file)
- generated_images (directory)
- space-pic1.jpg (file)
You can find more information about JSON lines here and a "results.jsonl" example for retrieval here.
In each run you can assign up to 10 images to the same argument ID. The rank key is used to determine the preference order of your images for the corresponding argument, where 1 is the most relevant image.
This means that if you submit for example 5 images for one argument you need to use the rank values from 1 till 5. Also this means that a run containing multiple image assignments for an argument with the same rank will not be valid.
You can find an examples for such multiple image asssignments to the same argument in the linked "results.jsonl" example. If there are any questions, please feel free to contact us.
Important Dates
- Dec. 18, 2023: CLEF Registration opens. [register]
- May 6, 2024: Approaches submission deadline.
- May 31, 2024: Participant paper submission.
- June 24, 2024: Peer review notification.
- July 8, 2024: Camera-ready participant papers submission.
- Sep. 9-12, 2024: CLEF Conference in Grenoble and Touché Workshop.
All deadlines are 23:59 CEST (UTC+2).
Evaluation
- The premises are usually formulated in general terms. This allows for some interpretation and choices of conveying images.
- If no rationale is given, we will use the prompt (generate) or automatically created (retrieval) caption as the default rationale.
- Try to avoid are very generic images, which get only only relevant though the rationale and show and could be used for many subjects will not get as many points as images that are premise specific. Also, if the generation approach is chosen, the image should not be too unrealistic, e.g., a person should not have four legs, although minor imperfections are are fine. See this section for further information.
Examples
Example 1
| Topic | Boxing should be banned |
| Premise | Boxing can cause serious injury to your body. |
| Stance | Pro |
| Claim | Boxing is dangerous. |
| Type | Anecdotal |
Submissions:
| Rationale | Heavy blows to the face are common in boxing. |
| Source | retrieved (Sweating fighter is punched in the face - gettyimages) |
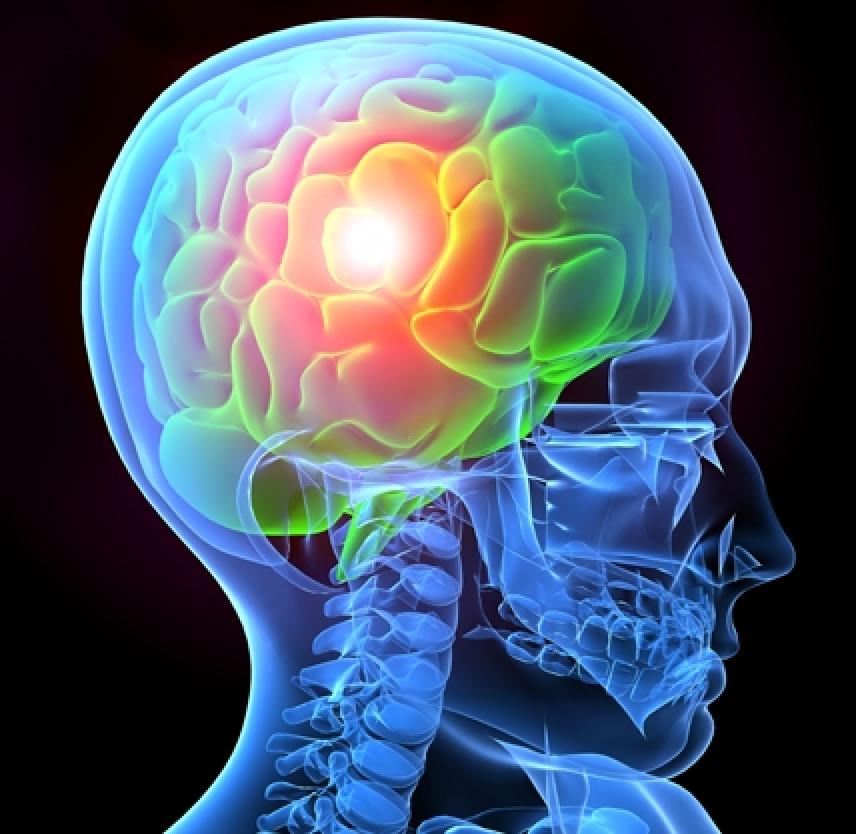
| Rationale | Concussion caused by heavy blows in boxing |
| Source | retrieved (https://www.shutterstock.com/de/image-illustration/headache-5407147) |

| Rationale | It causes a lot of pain and hurt. |
| Source | generated |
Example 2
| Topic | This house believes that democratic governments should require voters to present photo identification at the polling station |
| Premise | People will forget their IDs and cannot use their democratic right for voting |
| Stance | Contra |
| Claim | Use of Photo ID will result in exclusion of voters! |
| Type | Anecdotal |
Submissions:

| Rationale | People need to be reminded not to forget their ID. |
| Source | retrieved (Geoffrey Swaine/Shutterstock) |

| Rationale | Young Man in the voting station forgot his Photo ID. |
| Source | generated |

| Rationale | Photo IDs can be forgotten at home. |
| Source | generated |
Example 3
| Topic | Should performance-enhancing drugs be accepted in sports? |
| Premise | Performance-enhancing drugs create inequality in sports and undermine the essence of fair competition. |
| Stance | Contra |
| Claim | Performance-enhancing drugs should not be accepted in sport. |
| Type | Anecdotal |
Submissions:
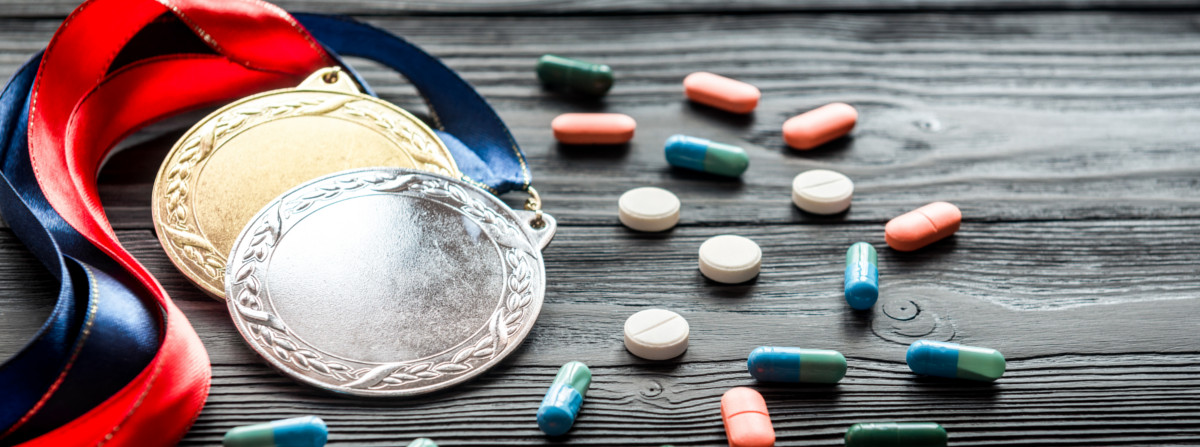
| Rationale | With performance-enhancing drugs, you can win medals you don't deserve. |
| Source | retrieved (https://sportsanddrugs.procon.org/) |

| Rationale | Hard training athletes cannot win if people are using performance enhancing drugs. |
| Source | generated |

| Rationale | Hard training athletes cannot win if people are using performance enhancing drugs. |
| Source | generated |
A comment on using images
As we can see from these examples, a rationale can be critical to associating an image with a premise. Try to avoid images that are too generic and only relevant because of the rationale. Look at the photo of the surprised woman. It is not possible to make a connection to the general topic of voting and photo IDs from the image alone. The connection to the issue is only made through the rationale. It gives the impression that this image could be used for any topic, such as a young woman being surprised about the dangers of boxing. Such images receive a lower relevance rating. The same goes for obviously incorrectly generated images, such as the bar through the athlete's head.
Example 1
| Topic | This house believes that democratic governments should require voters to present photo identification at the polling station |
| Premise | People will forget their IDs and cannot use their democratic right for voting |
| Stance | Contra |
| Claim | Use of Photo ID will result in exclusion of voters! |
| Type | Anecdotal |
Submission:

| Rationale | Young Woman forgot her Photo ID. |
| Source | retrieved (Image by benzoix on Freepik) |
Example 2
| Topic | Should performance-enhancing drugs be accepted in sports? |
| Premise | Performance-enhancing drugs create inequality in sports and undermine the essence of fair competition. |
| Stance | Contra |
| Claim | Performance-enhancing drugs should not be accepted in sport. |
| Type | Anecdotal |
Submissions

| Rationale | Hard training athletes cannot win if people are using performance enhancing drugs. |
| Source | generated |



